
AVE-TAL et ProfessorBob.ai : vers un assistant virtuel d’enseignement plus élaboré
Dans le cadre du projet AVE-TAL, les scientifiques du Laboratoire interdisciplinaire des sciences du numérique (LISN – Univ. Paris-Saclay, CNRS, CentraleSupélec, Inria) collaborent avec la start-up ProfessorBob.ai qui bouscule le secteur de l’éducation avec son assistant virtuel d’enseignement. La start-up s’appuie sur l'expertise de l'équipe du LISN en matière de traitement du langage et ses dernières avancées dans le domaine afin de développer plus avant sa solution.
Dans un contexte où 20 % des élèves sont en difficulté scolaire - soit un million en France* -, le tuteur virtuel ProfessorBob.ai propose, depuis juillet 2020, de prévenir le décrochage. Il est dédié aux élèves et professeurs de collèges, lycées, universités et formations professionnelles, afin qu’« ils et elles apprennent deux fois plus vite et retiennent trois fois mieux », selon son fondateur François-Xavier Hussher. Car un professeur ne peut personnaliser son cours lorsqu’il a 35 élèves dans sa classe. Pour parvenir à ce niveau d’apprentissage personnalisé, la solution mise sur l’intelligence artificielle et plus précisément sur l’apprentissage profond - un ensemble de méthodes d'apprentissage automatique fondé sur des approches mathématiques algorithmiques, utilisées pour modéliser des données - qui s’adapte aux profils en fonction de leur niveau.
Des expertises complémentaires
Pour fournir à ses clients un outil virtuel élaboré, ProfessorBob.ai se tourne, il y a trois ans, vers les scientifiques du Laboratoire interdisciplinaire des sciences du numérique (LISN – Univ. Paris-Saclay, CNRS, CentraleSupélec, Inria) et plus particulièrement celles et ceux de l’équipe Information langue écrite et signée (ILES). La start-up souhaite s’appuyer sur les dernières connaissances de la recherche en matière de traitement des langues via l’apprentissage profond. Elle se rapproche d’Anne Vilnat, enseignante-chercheuse au LISN et membre de l’équipe ILES, afin de lui confier le développement d’un système d’automatisation de questions et de réponses à partir de contenus de cours. « Au sein de l’équipe ILES, spécialisée en traitement du langage écrit, nous traitons des aspects compréhension, extraction et génération d’informations, aussi bien pour des domaines spécialisés comme l’informatique médicale, que pour l’enseignement », précise Anne Vilnat. Avec son collègue Gabriel Illouz, ils développent par exemple des outils pour générer automatiquement des QCM, afin d’assister les enseignantes et enseignants. Des compétences qui complètent parfaitement celles de la start-up : « ProfessorBob.ai maitrise très bien la recherche d’information dans les textes via l’apprentissage profond, mais pas le traitement de l’écrit », précise Gabriel Illouz.
AVE-TAL : automatiser les questions et les réponses
Leur projet consiste à concevoir un système capable de poser des questions et d’évaluer la qualité des réponses proposées, pour faciliter l’apprentissage des étudiantes et étudiants. « Souvent, l’étudiante ou l’étudiant moyen pense avoir compris et appris le cours en l’ayant relu une fois, mais en fait ce n’est pas le cas. L’outil envisagé doit lui donner la possibilité de s’entrainer de manière indépendante, ce qui, au passage, libère du temps de correction au professeur », explicite Anne Vilnat. En 2020, les scientifiques du LISN soumettent leur projet de recherche AVE-TAL (Assistant virtuel d’enseignement - traitement automatique du langage) à la SATT Paris-Saclay. Celle-ci signe le contrat de transfert technologique et finance le recrutement de deux ingénieurs et d’un post-doc, afin de faire le lien entre les compétences académiques et les ambitions entrepreneuriales en jeu.
Recueil du corpus de données et évaluation du système
Vu que les données que possède la start-up ne suffisent pas pour mener le projet, les deux enseignants-chercheurs du LISN font appel à leur collègue Patrick Paroubek, spécialisé en recueil de corpus de données et en évaluation du traitement automatique des langues au sein de l’équipe ILES. Car la tâche est complexe : seuls certains aspects du langage naturel sont formalisables et il n’est pas toujours possible de prouver que le programme d’extraction ou de génération de texte est performant. En outre, il n’existe pas de référentiel pour juger de la pertinence de la forme : « décider qu’un résumé est bon dépend aussi de l’appréciation de la personne qui le lit », éclaire Patrick Paroubek. Dès lors, il s’agit de collecter un corpus de textes, d’y appliquer à la main des annotations syntaxiques ou sémantiques, et de les comparer avec celles produites par la machine. « Cette opération statistique indique la capacité du système à résoudre la tâche qui lui est soumise », résume Patrick Paroubek.
Le traitement sémantique contextuel
Une fois recueillies, les données doivent ensuite être traitées. Depuis 2018, de grandes avancées dans les méthodes neuronales rendent l’analyse sémantique contextuelle possible. Conjugué à l’augmentation des puissances de calculs, l’apprentissage profond connait également une révolution : appliquer des algorithmes d’apprentissage sur de très grands ensembles de données est désormais envisageable. Patrick Paroubek explique : « Nous avons dépassé de nombreuses limites en matière de sémantique. Même si la machine ne passe pas encore le test de Turing, elle atteint aujourd’hui des performances comparables à celles d’un être humain sur certaines tâches de compréhension ». De cette manière, l’intelligence artificielle génère des exercices et questions élaborées, qui nécessitent d’agréger des informations éparses, présentes dans différents documents, et de les mettre en relation. Il est par exemple possible d’obtenir une réponse complète à la question « Qu’est-ce qui a provoqué la bataille de Marignan ? ».
Le périmètre d’AVE-TAL
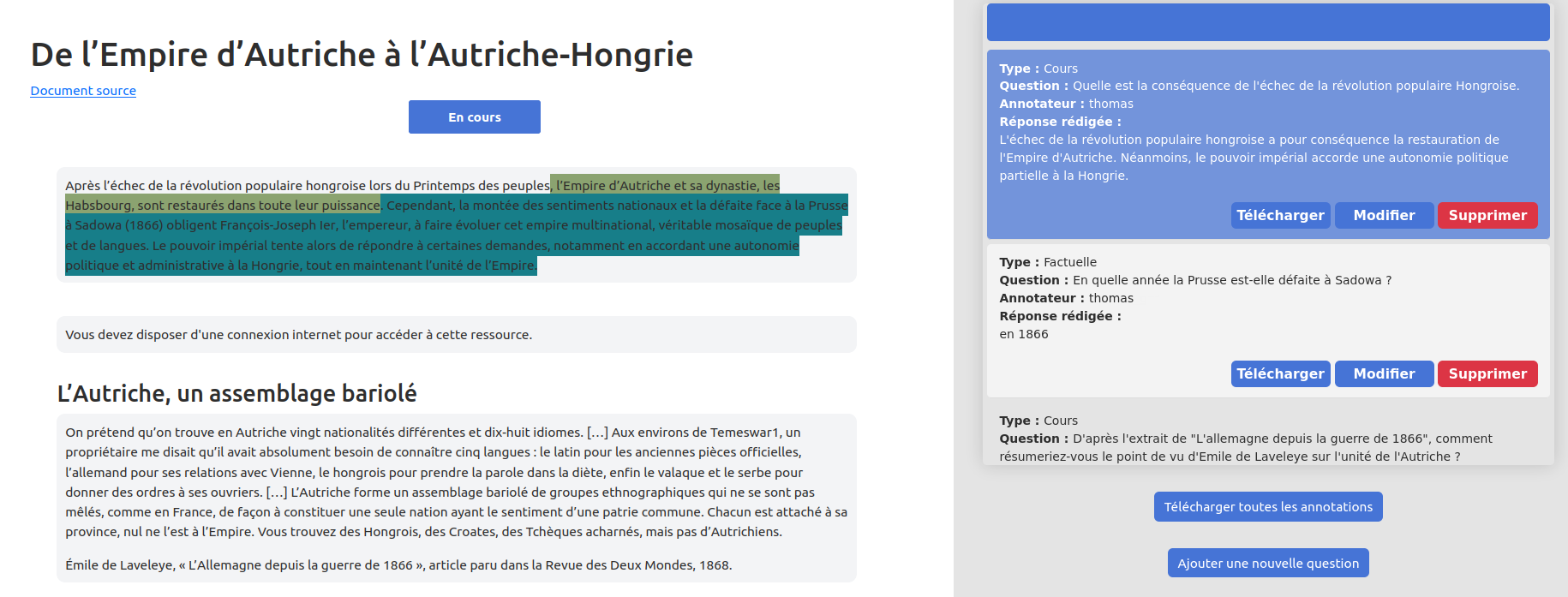
Dans un premier temps, AVE-TAL cible principalement l’histoire, l’éducation civique et la géographie, d’un niveau collège et lycée. Afin de garantir la fiabilité des informations, les données proviennent de cours d’enseignants et de manuels scolaires en français, libres de droit et validés par les enseignantes et enseignants. Grâce à un outil dédié, des annotateurs et annotatrices – enseignants et étudiants - spécifiquement recrutés produisent différents types de questions en lien avec des pages de cours. Elles et ils sélectionnent le passage où se situe la réponse et formulent la question. « Nous avons pour objectif de créer 10 000 questions. Puis, nous allons valider la méthode sur cet ensemble, afin de le faire évoluer, de l’étendre à de plus larges corpus de données, et de le transférer à d’autres disciplines et niveaux scolaires », commente Anne Vilnat. Ce transfert concernerait par exemple l'économie, la finance, le droit ou les mathématiques. En parallèle, l’interface d’annotation développée est mise à disposition des chercheurs et chercheuses qui souhaitent développer leurs propres expériences.
De grandes ambitions
À l’issue de cette première étape, s’achevant en juin 2023, le brevet d’exploitation de documents PDF déposé par la start-up pourrait être étendu à des fonctionnalités de traitement automatique des langues. Par ailleurs, la start-up compte à nouveau solliciter l’équipe du LISN pour lui confier de nouveaux projets de recherche. Comme celui de développer un système de dialogue avec les étudiantes et étudiants, afin de leur donner la possibilité d’approfondir des sujets de leur choix ; ou celui de mettre au point un agent dialogique proposant des réponses sous forme de vidéos d’apprentissage. « Comme la temporalité de la recherche et d’une entreprise ne sont pas les mêmes, nous apportons aussi à ProfessorBob.ai des services de conseil, pour cadencer les différentes phases des projets et évaluer les ressources et corpus nécessaires pour les réaliser », conclut Anne Vilnat.
*selon François-Xavier Hussher, fondateur de ProfessorBob.ai